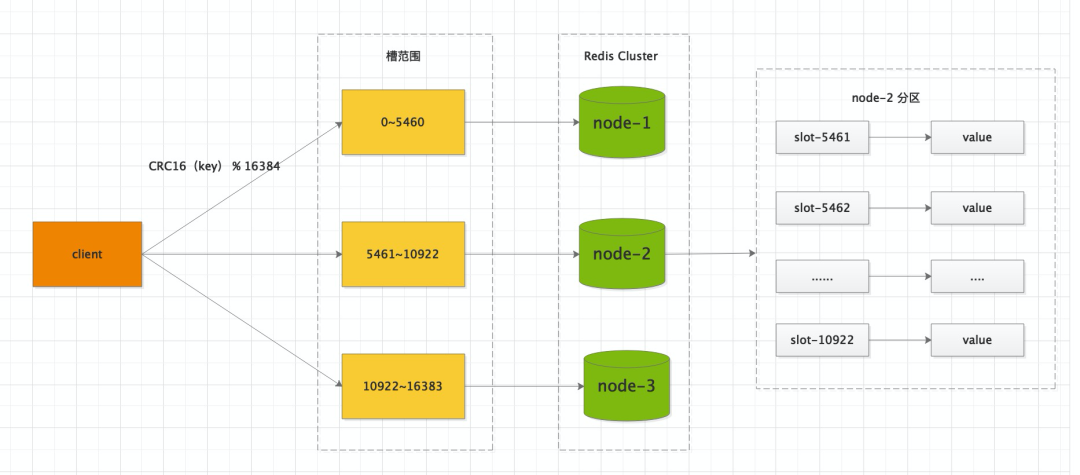
Redis Cluster 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽。集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么 node-1 包含 0 到 5460 号哈希槽,node-2 包含 5461 到 10922 号哈希槽,node-3包含 10922 到 16383 号哈希槽。
一致性哈希算法是 1997年麻省理工学院的 Karger 等人提出了,为的就是解决分布式缓存的问题。
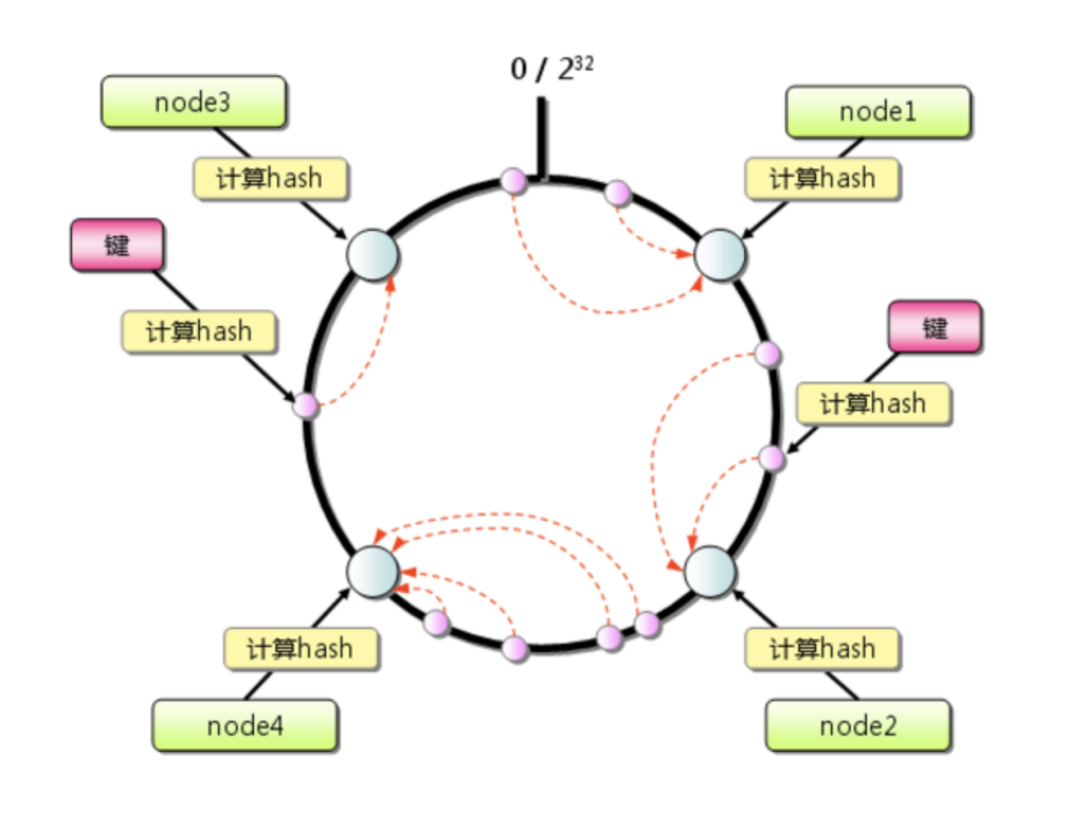
一致性哈希算法本质上也是一种取模算法,不同于按服务器数量取模,一致性哈希是对固定值 2^32 取模。
公式 = hash(key) % 2^32
其取模的结果必然是在 [0, 2^32-1] 这个区间中的整数,从圆上映射的位置开始顺时针方向找到的个节点即为存储key的节点
一致性哈希算法大大缓解了扩容或者缩容导致的缓存失效问题,只影响本节点负责的那一小段key。如果集群的机器不多,且平时单机的负载水位很高,某个节点宕机带来的压力很容易引发雪崩效应。
举个例子:
Redis 集群 总共有4台机器,假设数据分布均衡,每台机器承担 四分之一的流量,如果某一台机器突然挂了,顺时针方向下一台机器将要承担这多出来的 四分之一 流量,终要承担 二分之一 的流量,还是有点恐怖。
但是如果采用 CRC16计算后,并结合槽位与实例的绑定关系,无论是扩容还是缩容,只需将相应节点的key做下数据平滑迁移,广播存储新的槽位映射关系,不会产生缓存失效,灵活性很高。
另外,如果服务器节点配置存在差异化,我们可以自定义分配不同节点负责的 slot 编号,调整不同节点的负载能力,非常方便。

